
Data Science & Analytics
2021 NHL Expansion Draft analyzer
Data science app using Python and Streamlit to visualize sentiment from NHL fans and insiders on Twitter.
A data engineering journey towards modernizing NHL data
This is first of a series of posts that delves into exploring, organizing, and modeling on public Hockey (NHL) data. I am one of the two developers of this work alongside my colleague Gavin He. I will occasionally cross-post the cool work we do within our “organization” (called the-data-base) here on fullstaxx.
A modern application of data-engineering to enable data science on public Hockey (NHL) data for the purposes of learning & development
The motivation behind this project was simple: make public hockey data available using modern technologies for the purposes of data-science & data-visualization. We wanted to be able to answer questions like…
In order to get to this state of-course, a lot of data-engineering was necessary. Below is a visual representation of the project architecture.
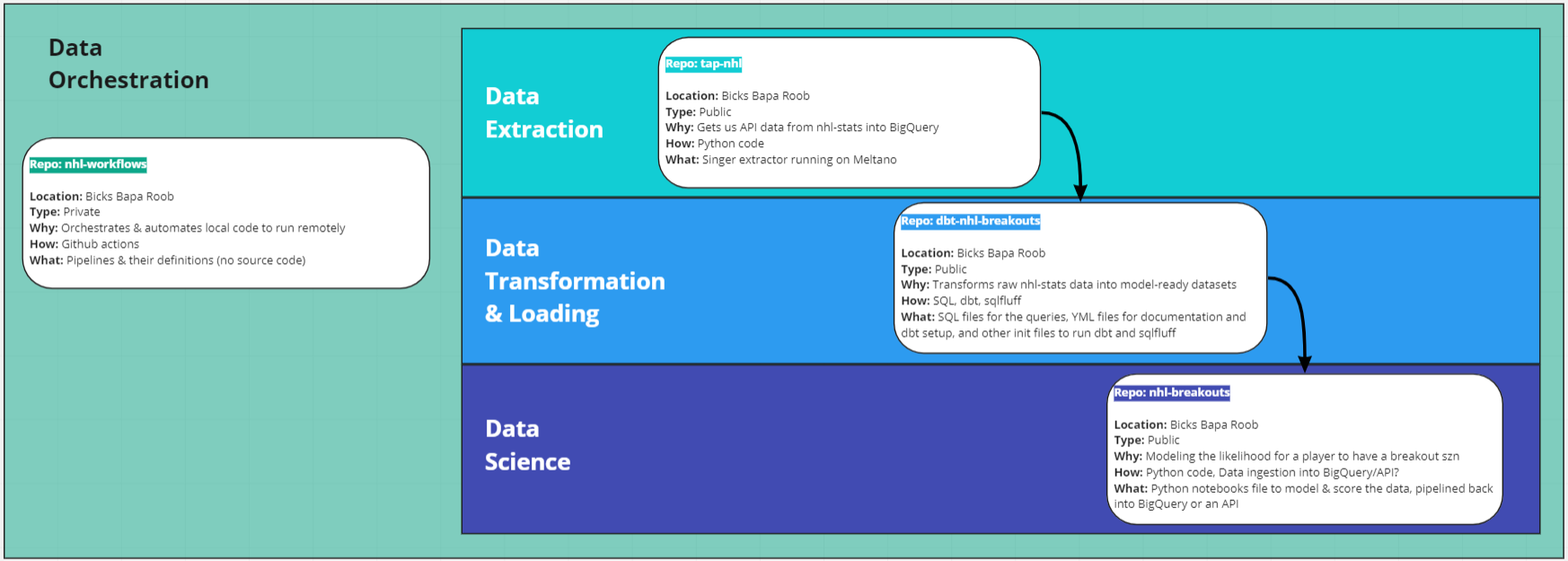
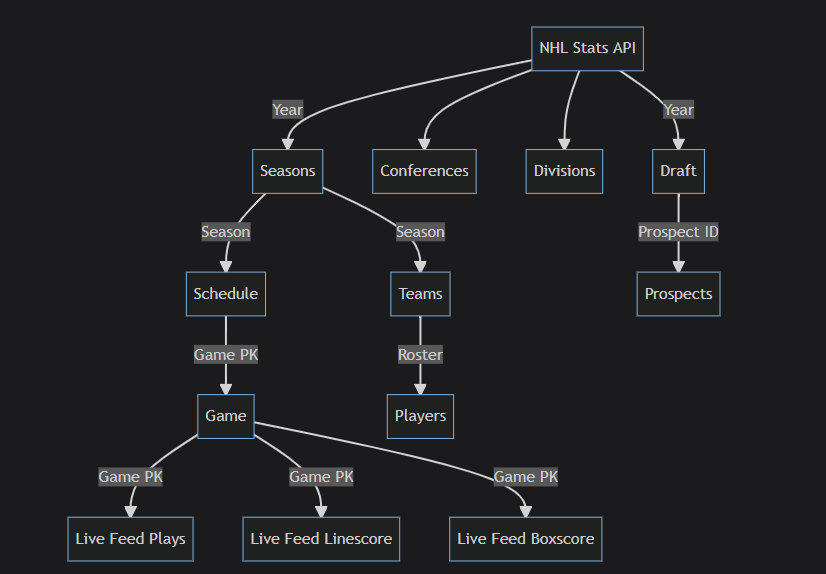
Currently, we only have a single source of data: the NHL Stats API. The Github repo that we built to extract the data is called tap-nhl. It is a Singer tap for the NHL Stats API.
Built with the Meltano Tap SDK for Singer Taps.
Below is a flow diagram explaining how it works:
Resources
All of this work is contained within a Github repo called dbt-nhl-breakouts and uses dbt to model our raw data. It contains the source code used to transform raw nhl data from the NHL Stats API into analysis-ready models.
In other words, this is where the SQL magic happens using dbt. Ultimately, this work converts confusing raw data into:
Resources
Consider this section separate from the rest. Each question that we decide to answer of our newly modeled data will live in this bucket. For example, one of the projects that spawned from this was the nhl-breakouts project
Data science app using Python and Streamlit to visualize sentiment from NHL fans and insiders on Twitter.